What Is Autonomy, Without Its Marketing?
Yesterday, HP agreed to buy UK software firm Autonomy Corp. for $10 billion to move into the enterprise information management (EIM) software business. HP wants to add IP to its portfolio, build next-generation information platforms, and create a vehicle for services. It is following IBM’s strategy of acquiring software to sell to accompany its hardware and services. With Autonomy under its wing, HP plans to help enterprises with a big, complicated problem – how to manage unstructured information for competitive advantage. Here’s the wrinkle – Autonomy hasn’t solved that problem. In fact, it’s not a pure technology problem because content is so different than data. It’s a people, process problem, too.
Here is the Autonomy overview that HP gave investors yesterday:
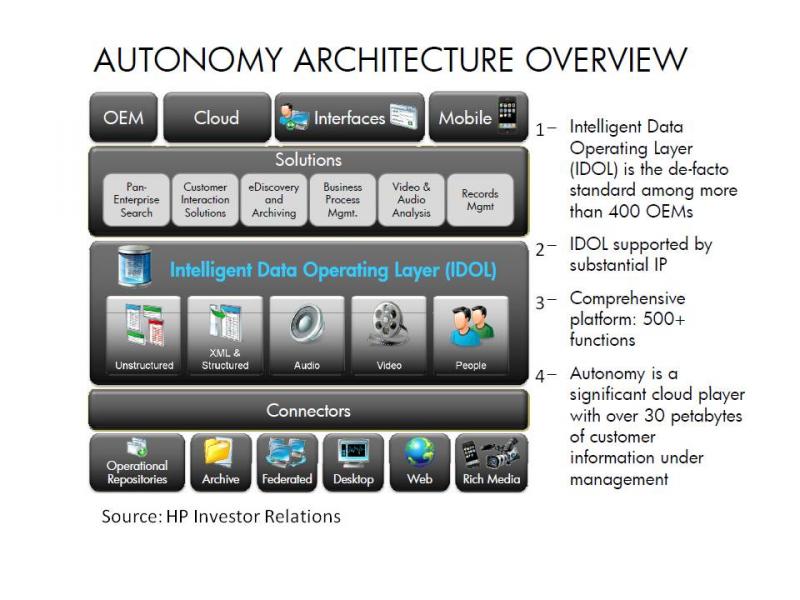
Of course, this diagram doesn’t look like the heterogeneous environment of a typical multinational enterprise. Autonomy has acquired many companies to fill in the boxes here, but the reality is that companies have products from a smorgasbord of content management vendors but no incentive to stick with any one of them.
Autonomy has well-regarded and established products in many areas of information management, especially pure search, content management, records management, and archiving. At the heart of Autonomy’s stack is the Intelligent Data Operating Layer (IDOL) — its brand name for search and content processing technology. It works by gathering up content, processing, storing, and serving it. Depending on the activity that IDOL supports (e.g., archiving, search, or eDiscovery), the size of the index varies. Customers may run instances of IDOL near the information source in order to keep the indexes close to the content. IDOL is like a vacuum cleaner with a huge vacuum bag and a lot of fancy ways to improve the dirt it collects. It isn’t an automatic fix to the challenge of information interoperability. You have to run the vacuum on the carpet minute after minute, night after night. And the vacuum bag grows. HP’s storage and server business will benefit from this consequence.
But I have a few issues with the narrative of the company as outlined in the architecture slide above (I added numbers to the text — 1-4):
1) Calling IDOL a “de facto standard” because a lot of vendors OEM it for search is misleading. IDOL isn’t vendor-neutral content integration middleware; if IDOL enabled interoperability, there wouldn’t be the need for the connector layer in the diagram. The fact that hundreds of information management vendors embed IDOL in their systems does not mean that the flow of information (migration, synchronization, accessibility, publishing) across these systems from different vendors is any easier. Each product has a small version of IDOL, and they don’t talk to each other.
Likewise, it isn’t any easier for an enterprise customer like GlaxoSmithKline to use IDOL for enterprise search against a content system that embeds IDOL versus a system that has different retrieval functionality. When IDOL indexes a content system, it connects to the back end where the content is stored; the search functionality in that system is not involved in this activity. This is similar to how I get no advantage in unlocking the front door of your house if your wife left a key on the inside front table.
In H1 2011, IDOL OEM revenue totaled $84 million (H1 2010: $67 million), up 27% and representing 18% of revenues. But I think the OEM market is increasingly threatened by alternatives. For example, ISYS Search Software, a small privately held company with system connectors and document filters like Autonomy, is used by leading IT vendors such as Sybase (an SAP Company), EMC, and . . . HP. Information management vendors that aren’t locked into Autonomy use Apache Lucene to deliver search functionality in their systems, or a best-of-breed specialist for capabilities like sentiment analysis.
2) The IDOL IP is stagnant. There hasn’t been a major release of IDOL in over 5 years.
3) IDOL is a platform with 500+ functions. If there’s an activity to do with information – categorize it, recommend it, filter it, search it, visualize it – Autonomy has an answer. That’s why it does so well in analyst evaluations of its software, including my own. But it does not sell an integrated information management product suite. Autonomy faces competition here from companies like Microsoft, which is beefing up its SharePoint offering to have more robust information processing and risk management capabilities. For details on the information risk management market impact, please see my colleague Brian Hill’s blog.
4) Cloud services are the second biggest segment of its business, but Autonomy is not a native cloud player in the way that salesforce.com, for example, is a cloud player. Autonomy stores information in its private cloud on behalf of enterprises for its Protect and Promote businesses. With its recent purchase of Iron Mountain Digital, it picked up additional cloud capabilities and significant volumes of data under management. But I don’t talk to clients who run information management applications like enterprise search with Autonomy in the cloud. Such clients are still evaluating issues of technical readiness and business-related issues regarding risk and cost.
Autonomy operates on a “pure software” model where most implementation work is carried out by approved partners. It will be a boon for HP services. But far from the integrated and complete EIM solution that HP laid out for investors, Autonomy represents a pile of technology that HP will need to make sense of.
____
Note: These 2 sentences were inserted for clarity on 8/26/2011: Depending on the activity that IDOL supports (e.g., archiving, search, or eDiscovery), the size of the index varies. Customers may run instances of IDOL near the information source in order to keep the indexes close to the content.