Beware The Automation Paradox
In 1983, Lisanne Bainbridge (a researcher at the University of Reading in the UK) wrote the following prescient words in her widely cited paper “Ironies of Automation“:
“By taking away the easy parts of [the] task, automation can make the difficult parts of the human operator’s task more difficult.”
In other words, automate all the easy things, and what’s left for people to do? The hard things.
This maxim has never been truer. When systems become too automated, their behavior in key respects becomes harder and harder to predict, and setting them straight when they go wrong requires deeper and deeper expertise. While we are in a world of dramatically increasing automation — chatbots, DevOps pipelines, AIOps, and more — the dark side is increasingly seen in problems such as the Boeing 737 MAX. When human factors are left out of the design process, and humans therefore cannot function effectively as a coordinated system with the automation, very bad things can happen.
On a less dramatic front, here at Forrester we are hearing signals that not all is well on the automation front. A few large but very competent clients have mentioned to me lately that mean time to restore (MTTR) is drifting upward, unexpectedly given their investments in trying to reduce it. Bob Davis of Plutora (a company that aggregates a lot of operational IT data) confirmed this in a conversation: “We’ve become sensitive to the topic of MTTR over the past six months as a measure of maturity. As customers get more sophisticated, we’re seeing unexpected behavior, with MTTR going up.”
Note that MTTR may not ultimately be a great metric to keep tracking; John Allspaw of Adaptive Capacity Labs has criticized it. But as it is such a widespread industry metric, I still believe it is a useful though imperfect signal, especially over larger-scale data sets and longer time horizons.
We also have statements from vendors such as Atlassian and Zendesk that the effective lifespan of knowledge articles is shrinking and the incidence of known errors (i.e., repeating incidents) is falling. This means that for any given incident, issue, or defect, there is a higher likelihood that it is a “zero day” concern (to borrow a term from security). Such concerns require higher skills — in classic service desk/NOC terms, it moves from Tier 1 to Tier 2 or 3.
And finally, there is the problem of Hollnagel’s law of stretched systems, which states that “every system is stretched to operate at its capacity; as soon as there is some improvement (for example, in the form of new technology), it will be exploited to achieve a new intensity and tempo of activity.” (Thanks to J. Paul Reed of Netflix for tracking the original source of this down for me.)
All in all, the contradicting dynamics (a classic balancing feedback problem) can be represented thus:
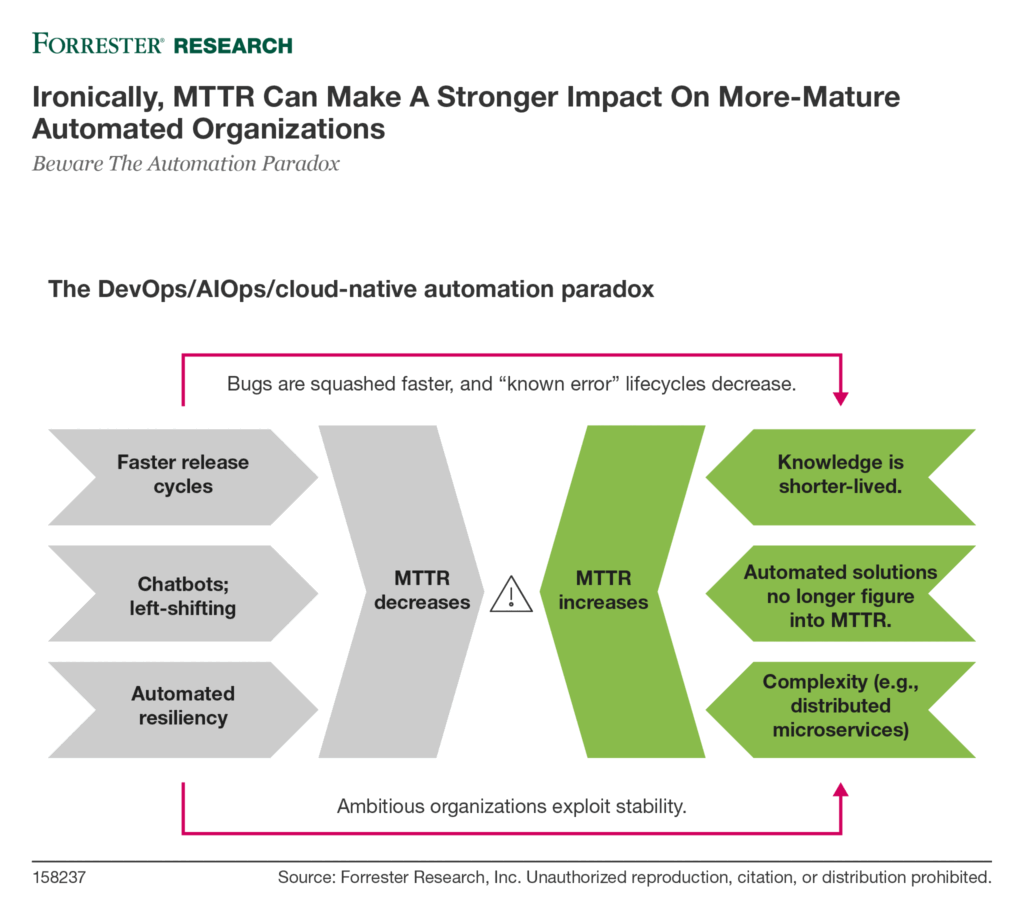
So what is to be done? It’s critical to recognize that this problem is inherent. It won’t go away. But in our latest report, “Beware The Automation Paradox,” there are some recommendations Chris Gardner and I make, including:
- Design the human/machine system as a unified whole.
- Embrace safety sciences and resilience engineering, including fields such as engineering psychology and human factors that have long studied these problems.
- Empower teams as your highest-value unit.
- Adopt the SRE perspective on automation.
- Use AI itself to help solve your observability problem.
- Adopt blameless retrospectives.
- Rationalize your automation portfolio.
Are you seeing any evidence of the automation paradox? If so, drop me a line. I will also be posting a brief pointer to this blog on LinkedIn and Twitter; since we do not allow comments here, I invite you to correspond with me via either of those channels.
NOTE: As part of this blog, I wanted to say a bit about Lisanne Bainbridge. It was surprising how little information about her existed; I actually found myself creating her Wikipedia page. I invite anyone with further knowledge of her to contribute to her legacy there.
Categories

