Elephants, Pigs, Rhinos and Giraphs; Oh My! – It’s Time To Get A Handle On Hadoop
By now you have at least seen the cute little elephant logo or you may have spent serious time with the basic components of Hadoop like HDFS, MapReduce, Hive, Pig and most recently YARN. But do you have a handle on Kafka, Rhino, Sentry, Impala, Oozie, Spark, Storm, Tez… Giraph? Do you need a Zookeeper? Apache has one of those too! For example, the latest version of Hortonworks Data Platform has over 20 Apache packages and reflects the chaos of the open source ecosystem. Cloudera, MapR, Pivotal, Microsoft and IBM all have their own products and open source additions while supporting various combinations of the Apache projects.
After hearing the confusion between Spark and Hadoop one too many times, I was inspired to write a report, The Hadoop Ecosystem Overview, Q4 2104. For those that have day jobs that don’t include constantly tracking Hadoop evolution, I dove in and worked with Hadoop vendors and trusted consultants to create a framework. We divided the complex Hadoop ecosystem into a core set of tools that all work closely with data stored in Hadoop File System and extended group of components that leverage but do not require it.
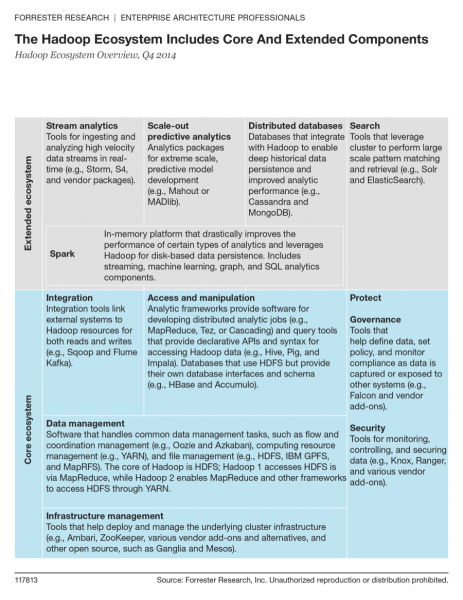
In the past, enterprise architects could afford to think big picture and that meant treating Hadoop as a single package of tools. Not any more – you need to understand the details to keep up in the age of the customer. Use our framework to help, but please read the report if you can as I include a lot more there.
A lot of this is wide open to interpretation. I’ll be updating this at least once a year, so chime in here if you have a different opinion of how Hadoop should be broken down. If I use your inputs I’ll send you a copy of the report as a thanks.
Categories
